
When we solve a machine learning problem, the algorithm that we may end up using depends on the type of data that we have and the problem itself. And despite having numerous algorithms to choose from, there is still a general procedure or framework that we follow to solve our problem.
In this post we will go through that generic process or framework which can be used as a template to solve any machine learning problem. After reading this article, you will –
- Understand the basics of Machine Learning
- See various steps involved in the Machine Learning process
- Get to know about other popular Machine Learning Frameworks
Machine Learning
Machine Learning is a field of study concerned with building systems or programs which have the ability to learn without being explicitly programmed. Machine learning systems take in huge amounts of data and learn patterns and labels from that, to basically predict information on never-seen-before data.

Here is a popular definition of machine learning:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
Tom Mitchell
I know this is difficult to fully comprehend so let me break it down into simpler terms – think of experience as data, the task to be predicting something with that data, and the performance measure to be the answer to the question of whether or not the prediction is actually correct. Now if you would like to get a general introduction to Machine Learning, check out this post –

Now that we understand what Machine Learning is, let us see how it is applied to solve interesting business problems.
Machine Learning Process
A process is defined as a series of actions of steps taken in order to achieve a particular end. Here, our process is achieving a successful implementation of a machine learning algorithm. The process begins with collection of data which is then processed and transformed in some manner. Then super cool machine learning algorithms are applied on it to make some predictions and derive impactful business insights. This is the basic framework of this process –
MACHINE LEARNING PROCESS
- Data Gathering
Gather data from various sources and combine to form one data structure
- Exploratory Data Analysis
Using Data Analysis techniques to study the data and derive insights
- Data Preprocessing
Now that we have an insight into how the data is, we perform some data preprocessing steps
- Model Selection
Selecting the machine learning model and training the model to create a baseline model
- Model Evaluation
Model gets evaluated based on test set and various performance metrics
- Model Tuning
As per the evaluation, we tweak the model by changing some hyperparameters or even going back and adding more data
- Model Predictions
When the model starts performing well during tests, it is then saved and deployed to be consumed – making predictions on new incoming data
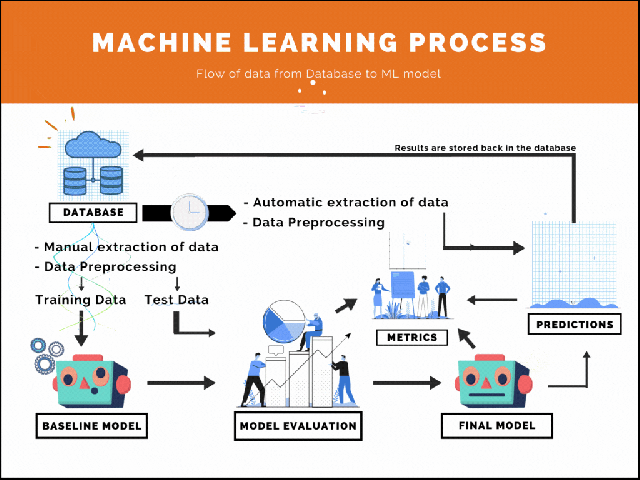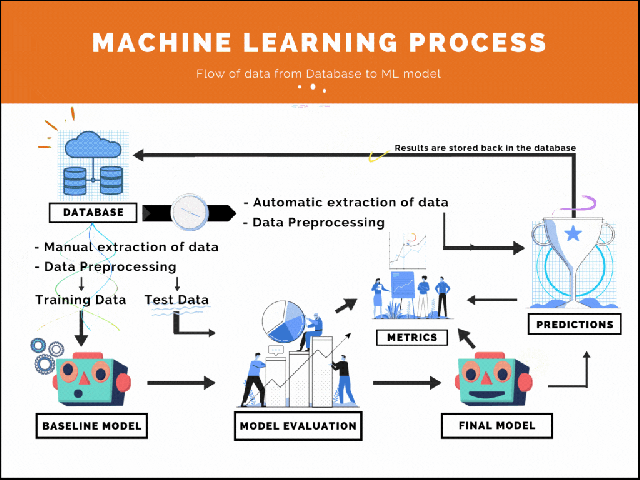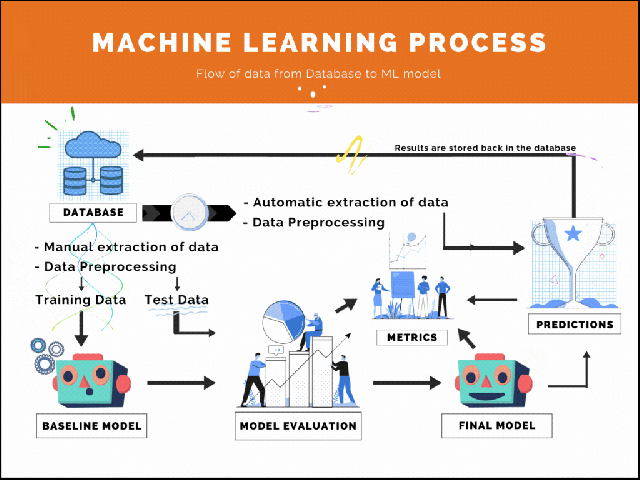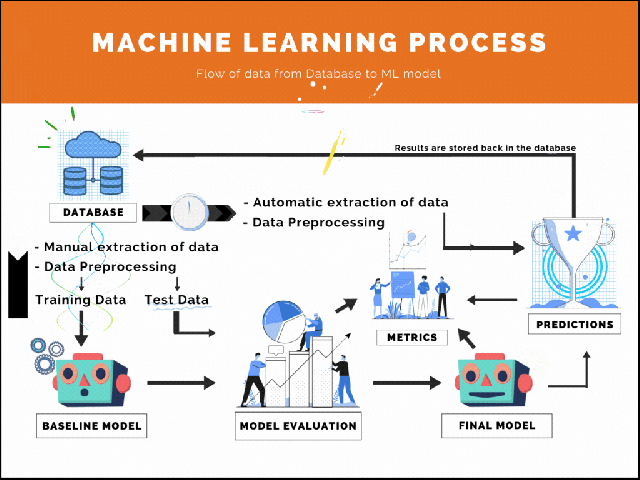
Now that we have laid out the framework, let’s go through each and every step to better understand the whole process. By the way, if you have applied machine learning to solve a problem before, you would know that the whole process is quite iterative. If you haven’t done it before, that basically means that you will apply a lot of the steps mentioned above until you get a result which is desirable. That desirability is calculated in step #5 with the help of evaluation sets and performance metrics which are completely defined by the problem statement. If you don’t understand this now, don’t worry about it, we will go through each step in the process.
Data Gathering
You might have heard the saying, “Garbage in, garbage out!”. If not, then you definitely will, almost every other day when working with data (no, seriously). Data is the most essential thing – if you have good data, then your model will have the best chance of performing like it is expected to and give out predictions which make sense in the real world.
Data gathering is the first step in the Machine Learning process and is defined as the act of collecting and combining all the data which is relevant to the problem we are trying to solve. This data is later used for training and evaluating our machine learning models. There are several challenges one might face during this step –
- The data we are trying to work with is not available in one place. Data from multiple systems has to be extracted and combined.
- This is a common industry problem and one has to rely on their data engineering skills to tackle this problem.
- First we have to find a way to extract the data from each system. We can use SQL to connect to the system databases.
- Use SQL to join the datasets somehow as per your requirement.
- Data is available but as a static file which one has to be manually exported from some system.
- For training and evaluation purposes, we can work with manually extracted datasets as it is a one time activity and we can re-use the same data for model selection.
- When we reach prediction stage, that is, when the final model has been deployed, we need to setup an architecture which automates this process of data extraction from the system, joins the extracted data if there are multiple systems, and then run it through some data preprocessing pipeline to bring it to the required format/structure. This is done so that no manual intervention is necessary and the machine learning model can consume data directly. Again, this is a data engineering exercise and we can define the flow to be something similar to this –

The data might be extracted from different sources and systems which do not necessarily have any way to communicate with each other so this activity is cumbersome and time-consuming. But an ETL Pipeline can help us in collecting data from various sources and store them in the desired format in a warehouse, ready to be accessed by Data Analysts and Data Scientists.
Exploratory Data Analysis
Before we build our machine learning model, we must study the data to know what kind of analysis we need to run and basically what kind of business questions we can answer with the data. This step is very closely tied up with the business problem we are trying to solve. And as the name suggests, in this step we explore the data by performing some analysis to find out what kind of features we have, how they are related, and use descriptive statistics to do some data visualization in the form of reports and dashboards. You are supposed to put on your investigator hat for this step here.

The data is imported from the place where we gathered it after the first step. There are several things which are found out at this step, things which go on to shape our methodology of how we are going to approach the problem. For starters, it is always good to have a good overall sense of the data and we can get a good idea by doing the following-
- Getting familiar with the data and its different features.
- Find out the relationship between those features and see if they are correlated.
- Find out the descriptive metrics of the data – the mean, median, minimum, maximum of important numerical features and most frequent, least frequent categorical features. There may be infinitely more metrics depending on the problem.
- Slice and dice the data by grouping it by various features to know the various possible combinations of feature values to draw insights on the variety of data we have. This helps in finding hidden patterns in the data.
- Find out the outliers in the data, by looking at the data by performing statistical tests (sometimes people can simply tell by simple intuition).
- Look for missing values and possible errors as well to handle them properly.
There are SOOO many more things you can do in this step. If you are really passionate about the data and the problem at hand, then this will probably be a step where you will spend a LOT of your time (trust me!).
Data Preprocessing
Now that we have studied the data, we know exactly what we have – this is a really important thing. We now have a much better idea how we should transform the data in order to run machine learning algorithms on it. For that to happen, the features that we have must be transformed. But before that, there are many other problems you have to think about – Missing data, incorrect data, duplicate values and so much more. The data is never clean enough to straight-away put into machine learning algorithms and that is exactly why this step is so crucial.

The features that we have may be of different types (which is mostly the case!) – numbers, categories, lists, free text or maybe something else. For machine learning algorithms to run, these features will have to transformed to such a state that the algorithm can understand them. We already have an idea that computers only understand numbers and that basically everything boils down to 0s and 1s (yes that also includes your embarrassing high school photos), and that is exactly what we try to do with our data preprocessing techniques. There are different techniques for different types of data that we follow. These are the common ones –
Numerical Feature
We check if the numerical feature is continuous or discrete.
- Continuous: This means that the feature values are continuous in nature measured over an interval of possible values.
- They are not still values and can take any possible value within that interval.
- A good example could be the temperature measured over a period of 48 hours.
- Another one could be the price of a house wherein the price could be anything say within [$70K, $700K].
- Discrete: This means that the feature values are fixed in nature and can only take up values from a set defined as per the problem.
- They are not necessarily whole number values but they are taken from a particular set.
- An example could simply be [0, 1] – either the value is 0 or 1.
- Another example could be shoe size say within [UK 6, UK 12].
Categorical Feature
We encode the categorical features. Encoding simply means assigning them a discrete numerical value or a vector value from a set.
- One-Hot Encoding: The feature column is split into the distinct number of categories in the column.
- So if we started with one column which contained categories [“bad”, “okayish”, “good”, “awesome”], now we have four columns.
- Each record which contains some category has the value 1 under that category’s column and 0 for the rest of them.
- “good” will now become [0, 0, 1, 0] and “bad” would be [1, 0, 0, 0] under the four columns [“bad”, “okayish”, “good”, “awesome”].
- Discretization: Another way is if we have the categories [“bad”, “okayish”, “good”, “awesome”], we can encode them like [0, 1, 2, 3] hence turning them into discrete variables.
- I believe this to be the more efficient method as instead of splitting the feature column into so many columns, we still have only one column.
Textual Feature
Textual features are encoded as well, but very differently than categorical features. There are several ways to encode text, but still all of them end up in the text being replaced by numbers. To do this, we first make something called as a vocabulary. The vocabulary is the list of all the unique words that are present in the text-based feature column (although I haven’t done it in the example below, the vocabulary can be sorted in an ascending manner). Here are the common ones-

- One-Hot Encoding: All the unique words are taken into account to form the vocabulary. Now there two ways to one-hot encode –
- First method says that each sentence is encoded with a vector which is the same length as the vocabulary.
- If a sentence contains a particular word, the vector position of that word in the vocabulary vector is marked as 1 and the rest are kept as 0s. Hence, a boolean vector.
- So the third sentence above will become – [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0]
- There is no sense of order, placement or significance of any word, it is just a boolean value.
- Second way for one-hot encoding is far more costly in terms of processing space and time. This is the same as before like we did for categorical features. Each word gets encoded with a vocabulary-length vector in which 1 is marked at the position of the word in the vocabulary if the word is present in the sentence while the rest are kept as zeroes. So finally if the sentence had n words to begin with, now it has been encoded with n vectors each having the same length as the vocabulary.
- Bag-of-Words: All unique words are considered to form the vocabulary.
- Here as well, each sentence is encoded with a vector which is the same length as the vocabulary.
- If a sentence contains a particular word, the vector position of that word in the vocabulary vector is marked as 1 and the rest are kept as 0s. If there are multiple entries for the same word, the count is added. Hence, we get a frequency vector.
- So a sentence like “my father is hungry like my cat again” would be –
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 2, 0, 0] - Even though there is now atleast some sense of significance as we are counting frequencies, still nothing about order and placement of the words.
- TF-IDF: This is the popular Term Frequency-Inverse Document Frequency algorithm.
- It is actually an extension, or an improvement over the bag-of-words method. Here, instead of having word-frequency vectors as the encoded values, we have vectors of tf-idf values.
- TF-IDF value for a word, at a high level, is calculated dynamically by multiplying the frequency of the word in a document with the inverse of number of documents it occurs in.
- TF is calculated and normalized by using the vocabulary and word-frequency vector from before –
TF = (frequency of the word / length of vocabulary)
– This will be still give a high value for common words like prepositions. So this alone is an incomplete metric. - IDF of a word is calculated by taking the count of documents the word is present in. Doing just this poses several problems so we make some modifications.
– If we take just the number of documents with that word as the IDF value, then it will be very high for common words.
– That is why we divide the total number of documents by the number of documents with that word in it, so that the words which are very common will have a low IDF value and the words which are not have a higher value. This is what ‘inverse’ document frequency means, and it provides with a sense of significance.
– But what if the total number of documents is HUGE and the denominator is not? The word will get a VERY HIGH significance. To somehow scale that value while still maintaining the sense of significance, we take the logarithmic value.
– Another mathematical modification is that for any fraction to give a value, the denominator must not be zero, hence we add 1 to the denominator finally giving us the following –
IDF = log(total number of documents / (1 + number of documents with that word in it)) - This is how we calculate the tf-idf values for each word and form vocabulary-length vectors for each sentence just like before, the only difference being that instead of word-frequencies, here we have the tf-idf values for each word.
- Word Embeddings: These are one of the most informative representations for a word, as word embeddings give a similar representation for words which are similar.
- The words gets mapped to a particular vector representation which has been found out by mapping all the words in a high-dimensional vector space.
- The words “car” and “bicycle” will be closer in that vector space than say “car” and “bed” and hence will get closer vector values, naturally capturing their meaning.
- This sort of meaningful space gives your machine learning system opportunities to detect patterns that may help with the learning task.

By the way, this is just the tip of the iceberg! When you start working on projects, one thing you will very quickly realize is that data preprocessing takes the most amount of your time. There is no set rule and it requires a thorough investigation from the previous step of EDA to get a relevant and usable dataset from pieces of information. Anyway, after all this investigation and preprocessing is done, the next thing to do is to split that data into two or three parts.

If you consider working as per best practices, then split the data into 3 parts in a ratio close to 60:20:20 (depending upon the size of your data), and make sure the data is split at random. There are various ways you can do this programmatically. The biggest chunk of the data goes to the Training set, and the rest is split into Validation set and Test set.
Training dataset: This is the dataset that will be used to train the machine learning model. The model learns through this dataset by considering all its characteristics and intricacies.
Validation dataset: This is the dataset which is used to evaluate the machine learning model after it has been trained. Maybe some model parameters need retuning, or maybe the entire algorithm needs to be changed.
Test dataset: This dataset is used to test the model on unseen data to check how well the model is able to understand its task and generalize to new data. This gives a sense of how well the model would perform in a real-world scenario.
If you would like to know more about data preprocessing, here is a comprehensive yet simple article on the same. Learn all about data preprocessing techniques, and ways to handle problems like missing data, incorrect data, feature encoding, dimensionality reduction etc..

Model Selection
After exploring, investigating and cleaning the data, we have a much better understanding of what needs to be done in order to solve the business problem. Model Selection is the step where we actually choose which algorithm will be the most appropriate to get relevant results with the current data. We start with a set of candidate models to finally settle on one chosen based on evidence.
There are several things to think about while choosing the algorithm. What someone has used in one of the tutorials to solve a similar problem may not always be the best choice as ultimately everything depends on the kind of data you are dealing with. There may be other constraints as well, such as model complexity, maintainability, deployment cost and resource availability which we will talk about during evaluation. The aim of this step is to create a baseline model which can be taken for further evaluation and fine tuning. The ideal scenario would be to train different candidate models using training data and compare them using validation data. But this sort of data-rich situations are hard to occur, so there are several other ways to do the same. For instance, you can use data resampling techniques like cross validation to train and test the different algorithms to choose the ideal one using the training data alone.

The model we choose is obviously dependent on the type of data that we have and the type of problem we are trying to solve. Say we want to build a chatbot. The chatbot will answer as per the user queries. So, we can say that the first step to any conversation will be the chatbot trying to identify the intent of the user, and there is our first machine learning problem — Intent Classification. This problem requires us to use a particular type of data — Text based data. The machine learning algorithm we choose must be a classification algorithm, that is, it classifies the new input data to a certain label class as per the data which it has already seen. Before this step, of course, the text from the user will get encoded and go through all the data preprocessing steps necessary and then it will be fed into the machine learning algorithm. All we have to do in this step is create a baseline model which takes in text input and classifies it to some intent class.
Model Evaluation
Now that we have a baseline model, we must work our way up to make this model production-ready. In this step, we will evaluate model performance against available benchmarks and business-defined KPIs and metrics. We always have a variety of tools and algorithms to solve a particular problem. As a data scientist, it is our duty to fit and test out various algorithms in all their relevant configurations. A good command over concepts like regularization, overfitting, underfitting and the various performance metrics like accuracy, precision, recall, confusion matrix and f1 score always helps. If we are working on some project, there is absolutely no way for us to know beforehand which model will perform the best on our data, so let’s talk about how evaluation is done. This is where the split we made in the previous step comes in handy. Here are a few things to think about –
Model Complexity
It is always advisable to start with a simple and naive machine learning model and work our way up to the complex ones. This is mainly because of these reasons –
- Simple models are easier to debug. It takes less time and effort to understand the architecture and make quick changes.
- Eventually everything boils down to the cost of running – Simple models are cheaper to run on the cloud mainly because they usually would have a lower processing time and much lower memory requirement.
- They are relatively easier to explain to the project stakeholders. Explainable AI is a big deal because if a business has deployed an AI model to assist them in situations, they need to be able to explain the model predictions to their customers.
Performance
We need to focus on model performance, may be there is a need to do some hyperparameter tuning, or maybe we need to switch the algorithm entirely. What we have to make sure when it comes to performance is that the model has been feeded the best possible configuration values, and that the results which come out actually make sense in the real world.
Project Requirements
Depending upon the problem, we may have a set of high priority metrics which need more attention. Like in case of cancer prediction, we not only need to be careful about false positives because that puts a high financial and emotional burden on the patient, but we need to be extremely sure when the model has said no, so that means we must have very low False Negatives (0 is the best number here, however unrealistic). So we need to be absolutely sure about the project requirements to define a “good enough model”. We need to know which KPIs and metrics are the ones that the business and project stakeholders are focusing on.
So we train different candidate models using the training data during model selection and then evaluate their individual performances using the validation data during model evaluation, both of which we created in the previous step of data preprocessing. Once you have evaluated the baseline model, it is now time to go through the results and think about what can be done to improve the model.
Model Tuning
After the model has been selected, trained and evaluated, it is now time to retune the model in order to somehow deal with the issues that have been highlighted in the previous steps. Model tuning, as the name suggests, is the step where we take feedback and results from previous steps of training and evaluation, to re-configure and retune the model in order to get a better fit.
This may involve changing the values of some parameters or hyperparameters, appending/removing data or simply switching how we are processing data in the data preprocessing step. It is all conditional to the kind of evaluation we receive from the previous step. As previously stated, ultimately it is the project stakeholder which defines the rules using which we can classify the model as being “good enough”, and if after evaluation the mode isn’t then we know that something needs to be changed.

Fortunately there are libraries like GridSearchCV which help us in automatically selecting and evaluating different combinations of hyperparameters for all the steps that we have designed starting from data preprocessing to model selection all the way till evaluation and fine tuning. Although computationally very expensive, this is very much considered as an industry best practice. It is supposed to be used only once so even if it is costly, it is all worth it as we can find out the perfect combination of hyperparameters without manually going back and forth and running the model again and again which might very well turn out be even more expensive.
These algorithms give us the most optimal values for all the hyperparameters while also creating that optimized model for us. So this way we don’t have to retrain the machine learning model using the new hyperparameters.
Model Predictions
Now that we have the most optimal machine learning model for the given problem, it is time to see how the model is doing on completely unseen data. If we still haven’t yet used the test set (again, this will be rare as most situations are not so data-rich) we can put the machine learning model to a test and see how it is doing on the test set. By now, we should not get alarmingly high number of mistakes as we have trained the model well and taken feedback to re-configure and optimize the model. But even if there are some niggling issues, we can always take a step back and adopt a debugging approach to get the matter resolved.

The main purpose of this step however, is not to address feedback, but rather design pipelines and setup the architecture to have a proper machine learning flow which does not require any human intervention at all for running the model and collecting its results. Designing machine learning pipelines is a challenging task, but one can always look up the documentation for a variety of examples and go through community help to build them.
- A machine learning pipeline will connect all the previous steps and run them together to produce a single well-trained and highly-optimized model object which can be re-used and deployed for scaling up the project.
- After we get this final model, we have to design a data preprocessing workflow so that any new data which comes in for prediction to the machine learning model is in the same state as the data which was used for training the machine learning model.
- So the new data coming from the data warehouse storage will go through the same data preprocessing steps as the training data did.
- There will be a connection from the model back to the data warehouse to store the results and use it for making reports and dashboards using data visualization tools and softwares like Tableau and PowerBI.
Other Machine Learning Frameworks
There are several other machine learning processes as well, but more or less they all tend to be very similar. Some focus on machine learning algorithm implementation while some focus on deployment flow. It is always good to consult all the frameworks if you are trying to establish a data-first organization and approach. I found these popular approaches to be useful –
- Yufeng Guo’s The 7 Steps of Machine Learning
- Francois Chollet’s Deep Learning with Python
- Joe Blitzstein and Hanspeter Pfister’s Data Science Process
- Matthew Mayo’s Machine Learning Process
So finally, we end the cycle here and the results for new data is presented to the project stakeholders for insight building and taking data-driven decisions. This is how an end-to-end machine learning project is designed and successfully executed. In this article, I wanted to give you a process or a template which you can re-use in your own projects. Applying machine learning to a completely new problem can be a little overwhelming and sometimes straight-up daunting. This machine learning process template will guide you and keep you on track with all the tasks you will have to perform along with potentially saving you a lot of time. Kindly like / subscribe to The Data Science Portal and share the article if you liked it and want to see more of such content!
Thank you for reading!






